We all think we have more time.
One way or another, you are going to soon receive an email telling you that the Software Bill of Materials (The SBOM!) that you asked for is ready for you. Maybe it’s coming from a Vendor, maybe it’s an internal project, maybe it’s from your own team. You suddenly have a very important document to review, and it’s hard to even know where to begin.
A big cause of paralysis in the security world is not knowing what to do next, especially with a seemingly buzzword heavy issue like this. Certainly everyone else knows what they are doing, but where do I even start?
I’m going to walk you through the basics of SBOMs, how to view them, some good first questions and where to go next.
What did you just receive?
A Software Bill of Materials (SBOM) is a listing of the third party software components that a software project uses in order to function. Typically this list of components consists of open source packages and libraries, but may also contain Commercially licensed components and possibly components with licenses that are neither Open Source or Commercial and may require further review.
We use this list of components to understand the software dependencies of this project, use it to identify potential security vulnerabilities, find end of life and unsupported software components, discover components that can be supported with money or software contributions, as well as discover other architecture or support issues.
This listing should include at least the name of the software component, its version and possibly information about the license it is released under. Beyond these basics, you may find additional pieces of information for these components such as Project URL, description, known vulnerabilities, etc. Since exchange formats and OSS scanners are still being defined, you may find yourself with varying levels of disclosure with varying levels of data quality and completeness.
The first thing to get a handle on is what type of SBOM you have received. There are a few different file formats and mechanisms for SBOM sharing, and more appearing every day.
What type of formats might you have received?
There are three main formats for SBOM sharing right now. CycloneDX, SPDX and free text files of varying complexity and origin. Typically, these files are designed to be both human and machine readable though it seems like the machines often have an easier time of it!
CycloneDX (https://cyclonedx.org/) is a file format created by the OWASP Foundation. You will know you have a CycloneDX file if your partner tells you that that is the format they will be giving you or possibly if the filenames are bom.json, bom.xml or end with .cdx.json or .cdx.xml
SPDX (https://spdx.dev/) is a file format created through the Linux Foundation. You will know if you have a SPDX file if your partner tells you that is the format they will be giving you or if the file name is similar to the following .spdx, .spdx.json or .spdx.rdf.xml.
Free Text, CSV or Excel Files are traditional text or spreadsheet files that contain SBOM information in one-off or less common SBOM formats. They may be created by a tool or a human and are often designed for human review instead of computer processing.
All of these file formats will contain information about the software components in use, many of the files will be “self documenting” meaning they will have Field Names (like Component Name or Version) near the data you are reading, or in a traditional spreadsheet format will have Column Names for each piece of data.
In a JSON, XML or free text file, component data often is spread out over multiple lines of text.
In a spreadsheet, each row is often a single component, where each column is the component’s metadata (e.g. name, version, etc…)
How to view and process the SBOM
The easiest way to get insights from the SBOM you just received is to run it through a SBOM scanner tool like Bomber. Bomber is a free and open source tool that can provide information about known vulnerabilities and license information for the open source components found in the supplied SBOM. Bomber can handle CycloneDX files in either JSON or XML format, SPDX SBOMS in JSON format, as well as Syft JSON SBOM files. If you have a file in a different format, you can use a free tool to convert it to one of these, or request your partner to resubmit it in a format you can handle.
See https://github.com/devops-kung-fu/bomber for installation and usage information. If using command line tools is new to you, this might be a perfect time to call one of your developers to work together.
Examining a SBOM file by hand (if not using a tool like Bomber)
While using a tool is much easier, it is possible to examine the SBOM files using a text editor and picking it apart by hand.
When looking at the JSON or XML files themselves in a text editor, you can find the component name, URL, version information and license information. For example, in CycloneDX the following tags are found near the information of interest:
“name” (the component name)
“version” (the component version)
“bom-ref” (the URL or similar locator for the component in question)
“license” (The license or license options for the component)
The license tag may be after a stretch of “hashes” or IDs used to describe the files that make up the component.
By using this information a web search can be used to find out vulnerability information. For example if you found Struts 2.3.31, you could do a web search using the terms “Struts 2.3.31 cve” and find out that this version of the component is affected by the vulnerability known as CVE-2017-5638 ( See https://nvd.nist.gov/vuln/detail/CVE-2017-5638 )
CycloneDX
For a deeper description of the CycloneDX SBOM format see https://cyclonedx.org/guides/sbom/OWASP_CycloneDX-SBOM-Guide-en.pdf
SPDX
For a deeper description of the SPDX SBOM format see https://spdx.github.io/spdx-spec/v2.3/
Many of these SBOM documents can be read in a standard text file viewer, or in a worst case, a Word Processor application. If the file is jumbled together or is in one long line, you will want to explore finding a more powerful text viewer that can better handle line breaks or special characters. Free tools like Visual Studio Code ( https://code.visualstudio.com/ ) can view Text, JSON and XML files. You may need to reformat the text if it is all in one line or jumbled together. In Visual Studio Code, Go to the Command Palette and select Format Document. The file should be more readable to a human now.
There exist JSON and XML file viewers which can make these files prettier to see and more useful to search or view.
Additional utilities are being released to support the use and viewing of SBOM documents in CycloneDX and SPDX formats.
A CSV or .XLS document can be opened in a spreadsheet application like Excel or Open Office.
Now That You Can View the SBOM What are you looking for?
One thing you can do is put it in a drawer! The very act of asking for an SBOM does a lot to kick the vendor into managing their third party risk. While this process works best if you ask them questions or give some pushback, asking for an SBOM allows them to say internally “our customer is asking for this, we need to do SBOM generation, SCA scanning, OSS Patch management, etc…
That said, you have it, let’s go get some value out of it!
This might be the point to bring in a developer if you are not familiar with open source libraries. There are a few things you can do on your own or you might find it is helpful to work together to understand the SBOM you just received.
There are a few questions we use SBOMs to help answer when looking at a piece of software
- Does the SBOM seem legitimate? Can you view it, read through it, see real data?
- Is it recently created? When was it generated? What version of the project was scanned? (e.g. is the SBOM wildly out of date?)
- Does the SBOM only contain “Top Level Dependencies” or does it include the dependencies of those dependencies, also known as Transitive Dependencies? This could be a difference of 3-10 times the number of actual dependencies seen!
- Can you find a few well known open source components and check their versions against the National Vulnerability Database (NVD) ( https://nvd.nist.gov/vuln/search )
- Are there well known vulnerabilities in the codebase (old versions of Log4j, OpenSSL, Apache HTTPServer, Apache Tomcat, Apache Struts)
- Does the list of component versions seem “too old”? Are all reported vulnerabilities from years ago (e.g. CVE-2017-5638 in Struts)
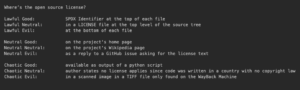
- Are there Open Source Licenses that might cause a problem for you? (Do you see licenses like the General Public License or Affero General Public License which might be contrary to your company’s license policy. This can be complicated since some parts of your company may happily use GPL software in Linux Operating Systems but may forbid it in distributed applications)
- Does it seem complete? Is it missing important information like version information?
- What software languages are seen? Do you see what you expect? Java libraries? NPM libraries? Is something missing?
Pushing back or Requesting More Information
After processing or examining the SBOM you may have some questions or feedback for the team that supplied it to you. Typically you might request more information about the highest security vulnerabilities or license issues found in the report. There’s a lot of discussion about how customers and suppliers can work together best to share and respond to SBOM and vulnerability questions. In general, especially if this is your first experience with SBOMS, you might find the most value in letting your supplier know you’ve run the SBOM through a vulnerability tool and you have some questions about what you are seeing. The idea is to gently (and perhaps later on, not so gently) work with your partner to reduce exposure to known vulnerabilities, as well as better provide their customers or end users with an explanation of why they are or are not affected. As you get more experience, you may find that providing 3 to 5 clear concerns can help your partner start to get a handle on your expectations, as well as chip away at the worst problems. For example, if you see that the software contains old high severity vulnerabilities in Log4J, Curl, OpenSSL etc,, this might be a sign that they have not been using SCA scanning or good vulnerability management practices.
Feedback from the Supplier
In general, throwing a list of 100s of problems back to a vendor will not be well received, especially if you are new to SBOM reviews. That said, getting feedback on 5-10 of the worst of the worst can give you a good feeling if they are managing their supply well or not. Many vulnerabilities may be present in an open source library, but not affect the software as you use it. A company should be able to clearly explain why they think they are not affected. “Trust me Bro!” is usually not a satisfying answer though. There should be clear explanations. For example, a good answer might be something like “This reported CVE only affects this component when run under the Windows operating system, and in this case we are using Linux”.
As time goes on the SBOM you receive from this supplier should contain fewer vulnerabilities, a more complete listing of third party dependencies, as well as explanations on why potential vulnerabilities seen in the codebase are not valid for their current usage.
Keep Requesting High Quality SBOMS
As mentioned before, one of the best side effects of requiring a SBOM to be delivered to you is that the team responsible for creating the SBOM will now put in place Software Composition Analysis (SCA) scanning tools, CVE/Vulnerability Patch Management, and processes in place to create/fix/deliver up to date SBOM information to you. A better understood product is a more secure product. The more SBOMS you see, the more that quality issues will pop out to you. Keep reviewing and keep giving and demanding strong feedback!